Advanced Guide to Parallel HTTP Requests in Laravel
Speed Up Your External API Integrations Using Http::pool() in Laravel
Making Parallel HTTP Requests in Laravel
Speed Up Your External API Integrations Using Http::pool()
Introduction
Most Laravel developers use the Http facade like this:
$response = Http::get('https://api.example.com/data');
But what if you need to make multiple external API requests and don’t want to wait for them one-by-one?
Laravel’s Http::pool() method allows you to send parallel HTTP requests, reducing waiting time and improving performance significantly.
This guide covers:
- Real-world use-cases (e.g., fetching GitHub repo data)
- How to handle failures and exceptions
- Performance comparison with sequential requests
- How to scale with dozens of concurrent API calls
When Should You Use Parallel HTTP Requests?
Use parallel HTTP requests when your application needs to:
- Fetch data from multiple external APIs at once
- Load multiple dashboard widgets or reports simultaneously
- Synchronize or enrich third-party data
- Run API-based scraping tasks efficiently
Understanding Http::pool()
Laravel’s Http::pool() method wraps Guzzle’s concurrency system in a simple, clean syntax.
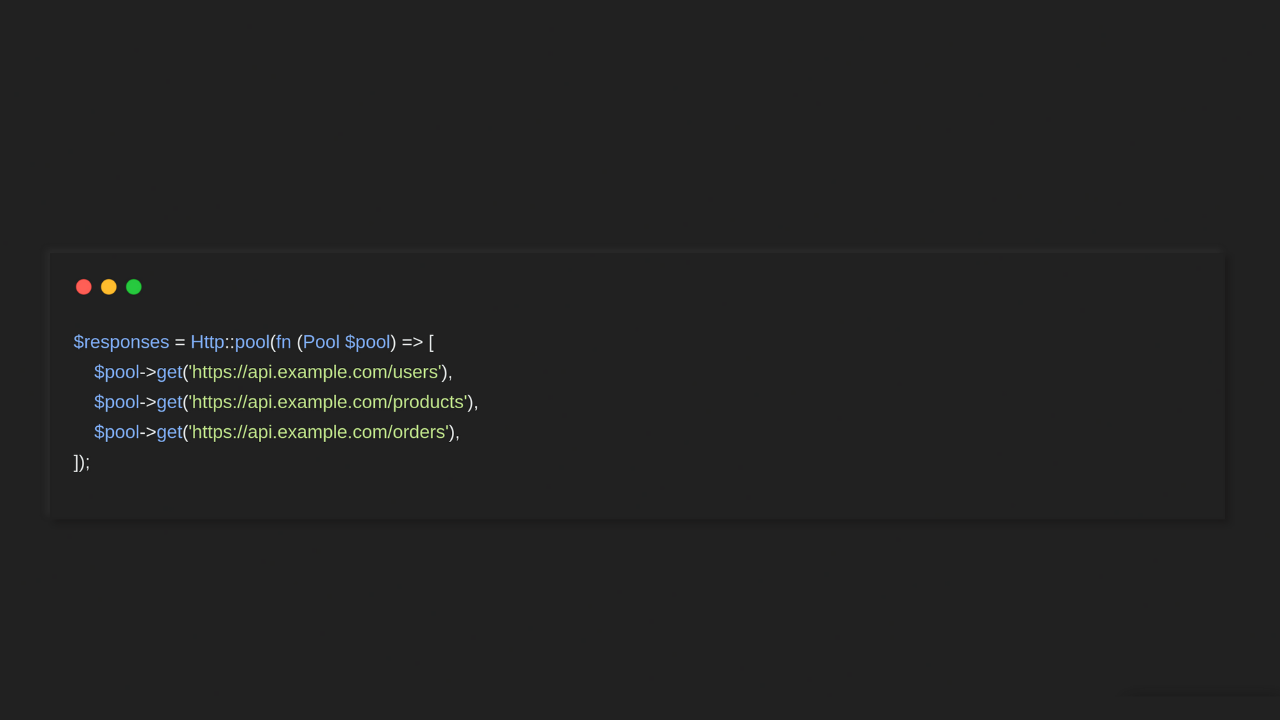
Basic Example
use Illuminate\Support\Facades\Http; use Illuminate\Http\Client\Pool; $responses = Http::pool(fn (Pool $pool) => [ $pool->get('https://api.example.com/users'), $pool->get('https://api.example.com/products'), $pool->get('https://api.example.com/orders'), ]); $users = $responses[0]->json(); $products = $responses[1]->json(); $orders = $responses[2]->json();
All three requests are fired concurrently, not one after the other. The total wait time will be close to the duration of the slowest request, not the sum of all durations.
Real-World Example: GitHub Repo Stats
Let's fetch public data for three GitHub repositories using the GitHub API:
use Illuminate\Support\Facades\Http; use Illuminate\Http\Client\Pool; $repos = ['laravel/laravel', 'symfony/symfony', 'vuejs/vue']; $responses = Http::pool(fn (Pool $pool) => collect($repos)->map(fn ($repo) => $pool->withHeaders([ 'Authorization' => 'Bearer ' . config('services.github.token'), 'Accept' => 'application/vnd.github.v3+json', ])->get("https://api.github.com/repos/{$repo}") )->toArray() ); foreach ($responses as $index => $response) { if ($response->successful()) { $data = $response->json(); echo "{$repos[$index]} has {$data['stargazers_count']} stars." . PHP_EOL; } else { echo "Failed to fetch {$repos[$index]}" . PHP_EOL; } }
This technique significantly speeds up batch API fetching.
Handling Failures
Always handle exceptions and unexpected responses properly.
foreach ($responses as $key => $response) { if ($response->successful()) { // Process data } elseif ($response->clientError()) { // Handle 4xx errors (e.g., Not Found, Unauthorized) } elseif ($response->serverError()) { // Handle 5xx errors } else { // Handle timeouts or connection issues } }
Benchmark: Sequential vs Parallel
Using microtime(true) you can compare request durations.
Sequential
$start = microtime(true); Http::get($url1); Http::get($url2); Http::get($url3); echo 'Sequential time: ' . (microtime(true) - $start);
Parallel
$start = microtime(true); Http::pool(fn (Pool $pool) => [ $pool->get($url1), $pool->get($url2), $pool->get($url3), ]); echo 'Parallel time: ' . (microtime(true) - $start);
Results will vary based on latency, but parallel execution can cut your total time by more than half.
Large-Scale Example: Dozens of URLs
Fetching GitHub data for dozens of packages:
$urls = Package::pluck('github_url'); $responses = Http::pool(fn (Pool $pool) => $urls->map(fn ($url) => $pool->timeout(10)->get($url) )->toArray() );
Best practices:
- Set a timeout to prevent stuck connections
- Use proper headers for rate-limited APIs
- Track index mapping if needed
Queue Integration: Run Parallel Requests in Background
For larger jobs or syncing, you can dispatch this inside a Laravel Job:
class FetchGitHubStatsJob implements ShouldQueue { public function handle() { $repos = Repository::pluck('slug'); $responses = Http::pool(fn (Pool $pool) => $repos->map(fn ($repo) => $pool->get("https://api.github.com/repos/{$repo}") )->toArray() ); foreach ($responses as $index => $response) { if ($response->successful()) { Repository::where('slug', $repos[$index]) ->update(['stars' => $response->json()['stargazers_count']]); } } } }
This is useful for syncing large numbers of repositories in one job run.
Custom Headers, Timeout, and Options
You can configure each request independently:
$pool->withHeaders([ 'Authorization' => 'Bearer ' . $token ])->timeout(10)->get($url);
Optional: Reusable Service Class
Extract reusable logic into a service:
class ParallelHttpService { public static function get(array $urls, array $headers = []) { return Http::pool(fn (Pool $pool) => collect($urls)->map(fn ($url) => $pool->withHeaders($headers)->get($url) )->toArray() ); } }
Usage:
$responses = ParallelHttpService::get([ 'https://api.site.com/users', 'https://api.site.com/products', ]);
Summary
- Use
Http::pool()to fire multiple HTTP requests concurrently. - It can improve API integration performance significantly.
- Always handle errors and edge cases carefully.
- Combine with Jobs for large or periodic background syncs.
- Abstract into services to keep your code clean and reusable.
This is a highly effective approach for building fast, data-rich Laravel applications that depend on multiple third-party APIs.